![]() 設計方法Design
Method
設計方法Design
Method
1【概說】
‧現代學術研究法則:「研究方法」(research method)vs.「方法論」(methodology)
‧工業設計「研究方法」與設計學「方法論」之必要性
‧工業設計研究方法:「設計方法」(design method)vs.「設計程序」(design
process)
‧產品設計的層次:New-Design、Re-Design、Re-Styling
‧產品設計程序的三階段:設計研究→設計發展→設計表達
‧工業設計的基本模式:
2【計劃】PROGRAMMING
定義:『對某一計劃案,列舉其一切有關之行動(作業)項目,並決定其必然發生次序。』
日程表(Schedule)
‧針對設計個案,依序列舉所有作業項目,標示開始日期或完成日期。
‧改良前種日程表管理技術之缺失,將作業項目填入固定格式之行事曆中。
甘特表(Gantt-Chart,Bar-Chart)
‧基本上亦由前種日程表之管理技術發展而來。以「時間」與「作業項目」分別為兩軸交叉成表,將預定進行之作業時間以條狀(bar)標示其上。
‧除原本計劃之條狀外,可以另色之條狀標示實際之執行進度,互相參照比對,以為管制、追蹤、考核之用。
‧簡單實用,誠為此法廣受採用之最大原因。
作業網技術(Network Technique)
‧為一種管理技術,應用「作業網」(Network)來規劃整個工作,可以標明形成整個計劃的每一個作業之間的相互關係,同時透過精密繁複的數學運算,系統化地研判評估整個計劃的各個構想及可行性,輕易地掌握住整個計劃案的全貌。
‧執行時,基本上大致可以區分為Planning、Scheduling、Follow-up(Control)三大步驟。
‧作業網技術產生的背景:
1.計劃的生產性
2.計劃的整體性與作業的關連性。
3.技術高度發展後的危險性
4.甘特表的缺點
5.俱良好管理工具之條件
‧作業網的三種基本記號:
1.箭線(Arrow) 表示一切需要時間的作業(Activity);箭尾意味著作業的開始,箭頭則意味作業的完成。箭線的長短與時間的長短無關。
2.虛業(Dummy)不需時間的「虛擬作業」,僅表示作業間的前後相互關係。
3.結點(Node, Event)標明時間的點(時點),表示作業的完成或開始。
‧繪製作業網的三條規則:
1.進到結點的所有作業全部完成後,方能開始從該結點出去的其它作業。
2.利用虛業表示作業間的相互關係。
3.在同一結點儘管可以同時進來許多箭線,但是這些箭線任兩條不能來自同一結點。(亦即:從同一個結點可以同時出去許多箭線,但此等箭線不能同時進到另外的同一結點。)
‧「分割作業」與「集中作業」
‧「出發點」(Source Node)與「最終點」(Sink Node)
‧「合流點」(Merge Node)與「分歧點」(Burst Node)
‧作業網應注意的錯誤標示狀況:
1.避免循環路線。
2.同一作業不能表示兩次。(不能有兩條箭線表示同一作業)
3.避免不必要的虛業。
‧透過作業網技術可以搜尋出「關鍵路徑」(Critical Path),並據以縮短所需工期。使時間及所有人力、資金、設備……等資源,得到最佳之「資源調配」(Resource Allocation)。
‧基本上較聞名的作業網技術有:PERT(Program Evaluation and Review Technique)、CPM(Critical Path Method)、RAMPS(Resource Allocation and Multi-Project Scheduling)、WSPCS(Weapon System Program and Control System)……等。
計劃評核術PERT(Program Evaluation and Review Technique)
‧以時間為對象來控制工作進度之方法。又稱「工作評估」、「方案鑑定與檢討方法」、「方案評核法」、「計劃評價檢討技術」……等。
‧此種管理技術乃利用「作業網」技術來規劃整個計劃,再利用數學來探討各個單項作業實際執行時,計算可能的開始時間、完成時間、以及「瓶頸(neck)」、「寬裕時間(float time)」…等,以作為管理與控制之用。
‧源於1956年,美國海軍特殊計劃局進行「北極星飛彈計劃」。Booz, Allen & Hamilton Co.
‧現已發展為利用「作業網」技術的一種系統化控制之方法,來促使各項資源的配置、成本的計算皆能最佳化。
‧後期之發展:PERT/Time、PERT/Resource、PERT/Manpower、PERT/Cost、………
‧「單時估算法」(Single-Time Estimate)與「三時估算法」(3-Time Estimate)
‧「關鍵路線」(Critical Path)、「寬裕時間」(Float Time)
‧「寬裕時間」含:1.自由寬裕(free Float)2.干涉寬裕(Interfering Float)3.總寬裕(Total Float)
要徑法CPM(Critical Path Method)
‧源於1957年,James E. Kelley(Remington Rand Co.)、Morgan R. Walker(Dupont Co.)兩位所進行之「工作的計劃與安排」(Project Planning & Scheduling)研究。
‧以「最少成本」(Minimum Cost),求取「最佳工期」(Optimum Duration)。
‧「正常時間」與「緊急時間」
3【收集】COLLECTION
‧就設計思維的觀點而言,設計其實可以視為一連串「探討」與「判斷」的過程。若希望整個設計過程能精確無誤地進行,就必須借助一些資料,來做為判斷時的參考及佐證。
‧這些經由各種方式搜集建立的資料,往往亦是形成最後結論的支配性因素。
直覺‧感知(直感法則)
‧主張「直覺」並不等同於主張「非理性」或「反理性」。
‧進行設計行為的主體為「人」,設計的目的也是為「人」;物質只是傳達設計概念與思維的媒介。而透過理則學的邏輯推斷,人不可能達到絕對理性的境界。既然如此,進行設計時不必要刻意去規避人類的直覺判斷。
‧人類天生俱有透過自身感官去察覺週遭事物的能力。經由長期的「學習/經驗」累積而成一套「個人知識系統」;每當新的外來刺激出現,便會就現有的「個人知識系統」,進行理解‧比對‧研判……等等一連串的內在思維過程,以認知外在環境的新事物;然後再吸收此一新概念,融入「個人知識系統」之中,轉化為個人潛在的本能與直覺。
‧一般而言,設計者擁有較常人更為敏銳的察覺能力。是以隨著設計經驗的累積,「個人知識系統」益形豐沛;面對設計問題時,便會具有更準確的直覺判斷能力及反應。
‧於省時省力的經濟考量下,就目前已知的現象及其它線索,設計者便可推理並歸結出若干結論,據以為設計時之參考。
‧善用直覺的觀察研判,針對設計問題藉由本能的思考得到判斷與結論;此一方法對一位具有豐富經驗的設計工作者而言,往往具有相當的幫助,同時在時效上也十分經濟。
‧發展出鋼筋混泥土結構型式的Nervi,亦認為在直覺的判斷之後,再加以分析和修正,可以有效地縮減摸索的時間,快速地求得解答,達成目的。
‧直感法則的優點和缺點:
科學性觀察(Observation)(觀察法則)
‧「觀察」可以說是一切知識的基礎。人類文明大部份經驗與知識,皆源於自身的觀察經驗及他人的觀察記錄。社會科學學者為學術研究之便,發展出不少研究方法,以提高觀察的有效性。是以設計者在進行設計研究,收集資料時,通常使用的方法之一,便是參考/應用一些社會科學領域的觀察方法。
觀察實驗的設計
.觀察法的決策:啟發式觀察、系統性觀察(systematic observation)
.觀察內容的認定:
.觀察法的型式:
.自然觀察法(natural observation):田野觀察(field observation)
.控制觀察法(contrived observation):
.選擇觀察者:
觀察法的分類
.行為觀察(behavioral observation):
.非語言之行為觀察(Nonverbal Behavioral Observation)
.語言行為觀察(Linguistic Behavioral Observation)
.超語言行為觀察(Extra Linguistic Behavioral Observation)
.空間關連分析(Spatial Relationship Analysis)
.非行為觀察(non behavioral observation):
.記錄分析(Record Analysis)
.物質狀況分析(Physical Condition Analysis)
.物質過程分析(Physical Process Analysis)
觀察者與觀察主題的關係
.「直接觀察」?亦或「間接觀察」?
.觀察者是否了解觀察主題?
.觀察者是否參與觀察現象的操作?
.觀察法則的優點和缺點:
文獻參考(Documentary)
.人類文明過去所累積的知識,皆記載成各種型式的文獻。透過研讀他人撰述之可靠資料,能有效地節省蒐集、整理資料的工夫,提高蒐集作業之效率。
.吾人通常將資料區分成『原始資料』(data)和『資訊』(information)。
.就產品設計工作的特性,以較廣義的觀點言,實物、樣品、相片……等亦或可認定為資料的特殊型式。
蒐集文獻資料的程序
文獻的來源
‧圖書館、製造廠商、販賣廠商、使用者、購買者、零售商、專家與學者、政府組織、徵信機構、研究機構、書店、其它、本人
文獻的形式
書籍
期刊
論文
型錄
報章、雜誌
正確性
佳
佳
佳
普通
差
完整性
佳
差
佳
差
差
時效性
差
佳
普通
佳
極佳
蒐集容易性
佳
佳
普通
差
普通
商品分析表:
.商品分析表的構成要項:
資料的評價
.資料的適用性:
.資料的正確性:(資料的品質)
資料蒐集的檢核表(checklist):
調查研究(Survey Research)
‧早在十八世紀,英國即已應用「調查研究法」於社會福利方面;然而時至二十世紀初才廣為其它各個社會科學領域所運用。
調查研究的程序
確定問題→擬訂假設→蒐集資料→分析解讀→撰寫報告
確定「研究課題」與「研究目的」
.描述性(descriptive):研究目的在描述實際的情況。
.因果性(causal):研究目的在驗證具有因果關係的研究假設。
.探索性(exploratory):研究目的在蒐羅有關研究課題的初步資料。
調查研究的內容(欲得資料的種類)
1.人口統計資料 2.經濟分佈資料 3.知識 4.心理因素 5.動機 6.態度 7.意圖 8.行為
詢問法(調查的型態)(questioning)
‧郵寄問卷(mail questioning):
‧電話訪問(telephone interviewing):
‧人員訪問(interviewing):
‧個人訪問(individual interviewing)
‧集團訪問(group interviewing)、深度集團訪問(focus group interviewing)
ps:『群體動力學』group dynamics
郵寄 |
電話 |
人員 |
|
| 彈性 | 差 |
好 |
很好 |
| 可蒐集之資訊量 | 好 |
普通 |
很好 |
| 訪員效應之控制 | 很好 |
普通 |
差 |
| 樣本控制 | 普通 |
很好 |
普通 |
| 資料蒐集速度 | 差 |
很好 |
好 |
| 反應率 | 差 |
好 |
好 |
| 成本 | 好 |
普通 |
差 |
抽樣(sampling)
「母群體」、「樣本空間」(population) 與「樣本」(sample)
前提:
1.母群體中的每一個體,有足夠的相似性(enough similarity)存在,是以部份的個體即足以表示出整個母群體的特性。
2.由於樣本中某些「個體特性值」是在「母群體母數值」之上,某些「個體特性值」是在「母群體母數值」之下;透過統計學理論之計算,可以求得「最佳推定量」。
優點:
1.降低時間、人力、費用……等成本。
2.縮短資料整理之時間。
3.可以獲得比較清楚之資料。
4.可以避免損壞被研究之個體。
抽樣計劃:
1.抽樣單位(sampling unit)
2.樣本大小(sampling size)
3.抽樣程序(sampling procedure)
抽樣程序:
1.決定抽樣方法。
2.找出母數(parameters)的推定值(estimates):母群體的「平均數」、「總數」、「比例」……
3.計算推定值之「標準差」(standard errors)。
4.建立母群體母數的「信賴區間」(confidence intervals)
5.推算「樣本大小」(size),並與抽樣計劃時所訂之「樣本大小」相比對。
抽樣方法:
抽樣之方法,可依「代表基礎」(representation Basis)與「元素選法」(element selection)兩項之採用方式不同,可分類如下表:
機率樣本 非機率樣本 非限制元素 簡單隨機抽樣
simple random sampling便利樣本
convenience sample判斷樣本
judgment sample限制元素restricted element 分層隨機抽樣stratified sampling 分層比例抽樣proportional allocation 配額樣本
quota sampleNeyman分層抽樣
Neyman's sampling method最適分層抽樣
optimum allocation samplingDeming's sampling、
sub-stratified sampling…系統抽樣systematic sampling 集群抽樣
cluster sampling:ex/area samplingPS:複合式抽樣法:二段抽樣法(two stage sampling )多段抽樣法(multi-stage sampling )
調查表(questionnaire)(問卷製作)
問題類型:問題的形式會影響到受測者的反應。問題的形式一般可以區分為兩大類型:
1.封閉式問題(close-end question):
2.開放式問題(open-end question):
調查表的基本要素:
1.面函 2.問卷本身 3.分類資料 4.編號
調查表的種類:
1.標準型(structured interviewing):
2.半標準型(semi-structured interviewing):
3.非標準型(non-standardized interviewing):
.談話式訪問(conversation interview)
.引導式訪問(guided interview/focused interview)
.非引導式訪問(non-directed interview)
調查研究優劣的評價指標:
1.客觀性(objectivity):度量所得之結果不會因人而異。
2.實用性(practicality):經濟性(economy)、便利性(convenience)、可解釋性(interpretability)
3.效度(validity):測量尺度能準確測定所欲知值的程度。
實際進行調查研究時,效度往往取決於「邏輯上的證明」和「統計上的證明」兩個因素。
.「內容效度」(content validity)
.「預測效度」與「同時效度」(predictive & concurrent validity)
.「結構效度」(construct validity)
4.信度(reliability):重覆對同一或類似母體進行調查,其結果仍然一致之程度。
所以可將信度視為「穩定性」(或「可預測性」)及「正確性」。
.外在的一致性程序(external consistency procedures)
.內在的一致性程序(internal consistency procedures)
調查研究優劣的評價指標:
■以「目標」區分:
1.測量受測者的各種特性。
2.測定給受測者的刺激(stimuli)。
■以「回答的形式」區分:
1.評等式量表(categorical or rating scale):
.圖式評等量表(graphic rating scale)
.項目式評等量表(itemized scale)
2.排列式量表(comparative or ranking scale):
.配對比較法(method of paired comparison)
■以「客觀的程度」區分:
1.受測者主觀的個人偏好(preference)。
2.客觀的非偏好(non preference)。
■以「量表的性質」區分:
1.比尺度量表(ratio scale)
2.間隔尺度/等距尺度量表(interval scale)
3.序數尺度/順序尺度量表(ordinal scale)
4.名義尺度/類別尺度量表(nominal scale)
■以「變數的多寡」區分:
1.單變數量表
2.多變數量表
■以「構成技術」區分:
1.隨意量表(arbitrary scale)
2.一致性量表(consensus scale)
ex:Thurstone氏「差別量表」(Thurstone differential scale)
3.項目分析法(item analysis)
ex:Likert氏「總合量表」(summated scale)
4.累積量表(cumulative scale)/葛曼量表(Guttman scale)
5.因素量表(factor scale)
ex:Osgood氏「語意差異法」(the semantic differential)
實驗研究(Experimental Research)
‧社會科學之研究,大體上可以區分為兩大類。
1.「非實驗法則」(non-experimental research),意指對研究對象原來之條件不加以改變,如前一章節所述之調查法即屬之。無需對照,只重視事實資料之累積。
2.「實驗法則」(experimental research),則相對地乃是透過實驗組與對照組之比較,用來決定變數之間是否有關連,以及其關係究竟如何的一種研究方法。自然吾人亦可借用此一法則,來收集並建立所需資料。
‧『實驗室實驗法』(laboratory study)與『田野實驗法』(field study)。
‧『自變數』(dependent variable,DV)『因變數』(independent variable,IV)
實驗法的效度
定義:「實驗結果反映DV與IV之間真實關係的程度」
1.內在效度(internal validity)
2.外在效度(external validity)
實驗法的研究設計
‧預實驗設計(pre-experimental design)
‧真實實驗設計(true experimental design)
‧準驗設計(quasi-experimental design)
實驗研究的步驟
1.標示實驗(label the experiment)
2.閱讀文獻(survey of the literature)
3.陳述問題(statement of problem)
4.假設說明(statement of the hypothesis)
5.定義變數(definition of variables)
6.實驗裝置(apparatus)
7.控制變數(control of variables)
8.選擇實驗設計之種類(selection of design)
9.研究對象擇取與分組(selection of subjects and assignment of group)
10.實驗步驟(experimental procedure)
11.資料統計處理(statistical treatment of the data)
12.編製證據報告(forming the evidence report)
13.由證據資料推測假設(making inference from the evidence report to the hypothesis)
14.實驗結論(generalization of the findings)
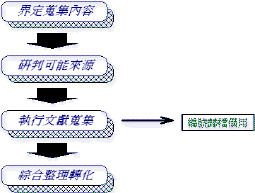
4【分類】CLASSIFICATION
無論採用任何方法進行蒐集資料,所蒐集來的大量資料,都必須加以處理,以方便下一階段的設計工作運用。
KJ法(K.J. Method)
‧1953年,川喜田二郎(日本籍,文化人類學學者),屬「定性資料處理」的方法。
‧在「書齋科學」與「實驗科學」之外,自稱此法屬「現場的科學」(野外科學)。能完整地掌握看似無法歸納/整理的各色事實內涵,藉由架構式的組織來進行統合,並發掘新的意義。是以川喜田氏自稱其為「創造性技法」。
‧KJ法所發揮的「加乘效應」(synergy)非常巨大,而「統合」與「組織」的結果,基本上可視為某一程度的『異質整合』。
KJ法的精髓:
1.強調「直觀重於定量數據」﹑2.創造﹑3.問題解決﹑4.意見溝通﹑5.團隊參與。
KJ法的基本態度:
1.捨棄自我 →自由(解放自我)
2.考慮他人立場 →愛
3.活用一切並加以統合 →平等
KJ法的實行程序:
pre-1. 主題決定
pre-2. 資訊蒐集
1. 紙片製作
2. 編組
3. A型圖解
4. B型文章化
層屬關係表(Hierarchy Chart)……問題的分解與組合
‧通常絕大部份的設計問題,都不是單一的設計命題;實際上往往是一組龐大的問題集合。面對這樣的現實,問題的「單純化」與「小規模化」,或謂「問題的分解」便成為重要且必然的思維路徑了。分解之後的諸多問題要素(小而單純的問題因子),必須再依據某種規則重新組織,方能掌握真正的問題全貌,這個過程我們稱之為「問題的組合」。是以,面對龐大複雜的問題時,必需建立一個具有層屬關係的系統架構,方能瞭解此複雜的設計問題之真正結構。
‧按此觀點,將問題依特定之某些準則,分解成許多的問題要素;再就所有的問題要素,以一定的基準進行分類,建立一個基本的系統化之層屬關係架構,使問題『可視化』(visualization),實乃處理複雜問題之不二法門。
‧KJ法,屬由下而上之『川型思考法』。由系統理論所衍生之層屬關係表法,則屬由上而下之『樹型思考法』。
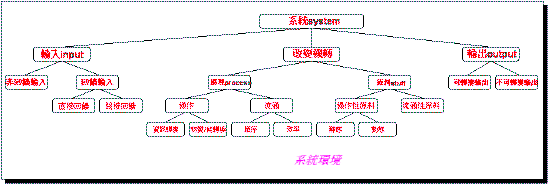
通用系統理論(General System Theory)
‧最基本的系統概念雛形,應該為一俱有層次的樹狀組織,作為其系統架構。
‧由上而下以「屬性基準」作為分類的基礎,可得到一個具有「層屬關係」的完整系統架構。這個過程可以視為………「問題的分解」。
同樣地,在某些設計情況時,如有需要亦可反其道而行,由下而上地得到另一個全新的系統;由異於現有系統的新見解,謀求嶄新的設計觀點。這樣的過程便成了………「問題的組合」。
‧隨著系統理論的日趨完備,發現在原本定義之下的「系統」外,尚有另類系統的存在。此際,方才發展出「開放系統」的概念;而相對於此,早先定義的系統(狹義的系統定義)則稱為「封閉系統」。
‧「靜態系統」與「動態系統」:
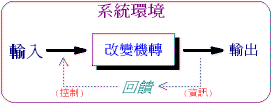
動態系統的構成要素:
1.輸入(input)
2.輸出(output)
3.改變機轉(changed mechanism)
4.迴饋;回授(feedback)
5.系統環境(context)
基於此一「通用系統理論」,導入「動態系統」的概念,可建立一個通用的「基本系統模型」。事實上,就工業設計的實務經驗而言,亦可善加運用「系統理論」的觀點,將問題系統化加以處理,以幫助設計工作者瞭解問題全貌,並進行各項設計工作。
‧設計問題系統化的另一優點,有助於數量化設計方法的導入。
‧Laszlo氏的「通用系統理論」(General System Theory)告訴我們,當系統面臨「複雜化」(complex)的問題時(……源於牽連到過多的『參數』(parameter);或是因為參數間過度密切的「相互作用」(interaction),導致「系統參數層次」(system level)上的「秩序性」及「屬性」之『群聚性質』不明顯),此際就必須運用其它比較複雜的統計解析工具了。
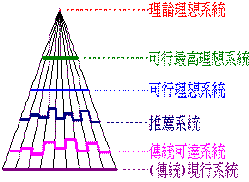
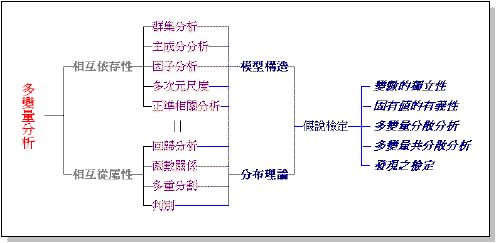
‧理論上,任何的設計命題,都會有許多不同層次的系統,可成為其解答。依Nadler氏的看法,如果我們先找出其「理論理想系統」,規劃完成整個最高的理論理想系統之後,再分別推斷其下階的各層系統,由此尋找出最合適的解答;如此在時間和其它方面,往往比較符合經濟效益原則。多變量分析(Multivariate Analysis)
‧1931年,美國心理學者Thurstone L.氏為研究所需,在傳統統計學的基礎上,開始發展非單一變數的數據處理/解析技術。
運用「多變量分析」的目標:
.事象之簡潔陳述。
.影響要因之查定。
.要因之結合法則。
使用「多變量分析」的目的:
1.問題構造之單純化
2.分類
3.變數之群化
4.變數相互依存性之解析
5.變數相互從屬性之解析
6.假說之設定
7.假說之驗定
y=f(x),各個學術領域的稱呼
外在基準y 內在基準x 社會科學 基準變數 (目的變數) 說明變數 (潛在變數) 經濟學 外生變數 內生變數 統計學 從屬變數 獨立變數
線性回歸:
1.線性模型(linear model):
y=α1x1+α2x2+……+αpxp+ε
2.雙線性模型(bilinear model):
y=α1x1+α2x2+……+αpxp+ε
xj=aj1f1+aj1f1+……+aj1f1+εj (j=1,…,p)
尺度(scale)的種類:
計量尺度
metrical scale比尺度 (ratio scale) 間隔尺度 (interval scale) 非計量尺度
non metrical scale序數尺度 (ordinal scale) 名義尺度 (nominal scale) 主要的幾種多變量分析方法:
1.重回歸分析法(multiple regression analysis)
2.判別分析法(discriminant analysis)
3.正準相關分析法(canonical correlation analysis)
4.因子分析法(factor analysis)
5.主成分分析法(principal component analysis)
6.群集分析法(cluster analysis)
7.多次元尺度法,多向度法(Multi-Dimensional Scaling;MDS)
多變量分析法之分類:
說明變數 基準變數 名義尺度 間隔尺度 名義尺度 間隔尺度 有外在基準 重回歸分析 多數 1 正準相關分析 多數 多數 重判別分析(正準分析) 多數 多數 (線型)判別分析 多數 2 數量化一類 多數 1 數量化二類 多數 多數 主成分分析 多數 (多數) 特異值分解 多數 (多數) 無外在基準 雙對尺度法(數量化三類) 多數 群集分析 (多數) 多數 因子分析 (多數) 多數 使用類似性指數 數量化四類、多次元尺度法、最小次元解析、潛在構造分析 多變量分析的範疇:
群集分析(cluster analysis)
定義:「對個體間的親緣性加以數量化之評價,使分類成有秩序之體系組織。」
‧群集分析法為一種量化的「階層性分類方法」(hierarchical method)
‧「類似度」(similarity)
「非類似度」(dissimilarity)………「距離」(distance)
分類學(classification)簡史:
18世紀 博物學者K. Linne氏創『二名法』,以屬名與種名表示 動、植物 之分類。
M. Adanson氏以更多的特徵為依據,進行分類。
1938年 Zubin氏提倡自然科學以外的學術領域,亦可採用分類 學的方法。
1953年 Thorndike氏確立「數值分析法(numerical taxonomy)」。
1957年 Sneath氏建立「群集分析(cluster analysis)」方法
1963年 Sneath & Sokal氏定義「群集分析法」。
1971年 Cormark Ball氏建議使用「群集分析法」的時機。
「群集分析法」的使用時機:
1.探尋真正的類型
2.尋找適用的模式
3.群化(grouping)之預測
4.data之探察
5.data之集約
6.假說之檢定
7.假說之形成
群集分析計算距離的幾種方式:
1.euclidian distance
2.city-block distance
3.minkovsky matrix
4.…etc.
‧模式類似率(pattern similarity)、偏差模式類似率
‧二值變數(binary data/0-1 data)一致係數(matching coefficient)
‧類比率(similarity ratio)
群集分析的幾種計算方法:
A.階層的方法
1.最近鄰法(單連結法)
2.最遠鄰法(完全連結法)
3.重心法
4.中值法
5.群平均法
6.伍德法
7.階層模式法
B.非階層的方法
1.最適化法
2.密度探索法
3.其他
5【解析】
Analysis
經由初步分類及整理之後的「原始資料」(data),基本上已經轉化成為可以使用的「次級資料」(資訊,information);但是無論經由何法所得之問題系統(問題構造),仍然不足以幫助設計人員做出準確的研判,以便進行下一階段的工作。顯然地,我們還需要尋找或發展一些其它的工具(設計方法),來協助設計工作者完成專業上的思考……。
次序矩陣(Rank Order Matrix)
於諸多要素之間,評比某項性質且據以排列順序,並非易事。當被排序之要素為非計量尺度(non metrical scale)時,因無法統一量化,尤其困難;勢必兩兩比較,方可得知答案。
‧「次序矩陣」的實施步驟:(略)
‧在實際操作時,「次序矩陣」提供了一個清楚可視的方法,方便一目瞭然地發現設計要素的重要程度之優先順序。ex:
A
B
C
D
E
F
G
H
I
J
A.
▲
▲
▲
▲
▲
B.
▲
▲
▲
▲
C.
▲
▲
▲
▲
▲
▲
▲
D.
E.
▲
▲
▲
▲
▲
▲
▲
▲
F.
▲
▲
▲
▲
▲
G.
▲
▲
▲
▲
▲
▲
H.
▲
I.
▲
▲
▲
▲
▲
▲
J.
▲
▲
▲
score
4
5
2
9
1
4
3
8
3
6
rank
5
4
9
1
10
5
7
2
7
3
相關因素表(Interaction Factors Matrix)
‧「次序矩陣」僅能排列各個要素的優先順序,卻無法顯示各個要素(因子、因素)之間的關係。事實上,當被評比之要素,彼此之間互有關連,非為「獨立因素」(independent factors)時,使用「次序矩陣」排序的結果並無太大意義。
‧使用時機:系統化地探討各要素間的關連性時。
‧Gregory氏指出;「相關因素表」是系統設計方法研究當中最有效的方法之一。
J. C. Jones氏亦認為;「相關因素表」的主要價值在於可以正確地進行檢核,而非憑空想像
「相關因素表」的實施步驟:
1.選擇適當的因素,並加以明確定義之。
2.界定「關連性」之意涵,並建立一定之序數尺度(ordinal scale)。
3.製作矩陣,相互比較。
4.以客觀之關連性為評比基準,賦予每一對因素恰當評點。
注意事項:
1.各因素的系統層屬關係,務必同一水平。
2.關連性的評核作業相當耗時耗力。是以,矩陣因素數最好限於20以內;或是將之分解成若干個較小的矩陣,再行處理。
3.基於同一理由,關連性的尺度,以二階或三階行之較好。關連性的基準不宜太鬆。
A
B
C
D
E
F
G
H
I
J
A.
●
●
○
●
●
○
●
●
●
B.
●
●
○
○
○
○
●
○
○
C.
●
●
○
○
○
○
○
●
○
D.
○
○
○
○
●
●
○
○
○
E.
●
○
○
○
○
●
○
○
●
F.
●
○
○
●
○
●
○
○
○
G.
○
○
○
●
●
●
○
○
○
H.
●
●
○
○
○
○
○
○
○
I.
●
○
●
○
○
○
○
○
●
J.
●
○
○
○
●
○
○
○
●
Alexander氏「策略組件法」(Alexander's Method of Determining Components )
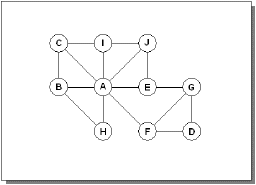
相關網(Interaction Network)
「相關網」銜接了「相關因素表」,使各因素間的關連性,以視覺的形式表現。或可稱之為「問題的構造」。
「相關網」的實施步驟:
1.先建立「相關因素表」。
2.以點代表「因素」,線條代表「關連性」;進行轉化。
3.調整各點的相關位置,使線條間的交叉減至最少為止。
6【總成】
檢核表(Check List)
‧奧斯本的「創意檢核表」:
綜合歸納
7【發想】
形態學分析表(Morphological Approach)
聯合分析(Co-Joint Analysis)
腦力激盪術(Brain Storming)
提喻法(Synectics)
屬性分析表(Attribute List)
8【形塑】
Image Scale Map
場景情境法(Scenario)
Image Board
其它